



子供にとって毒か薬か「人間の脳と生成AIの違い」
生成AIと人間の言語システムには、決定的な違いがある─それにもかかわらず、今、言語習得過程にある子どもたちに「おしゃべりする生成AI」が手渡されようとしている。2児の父でもある言語学者が、切実な危機感を込めて警鐘を鳴らす。
教育

生成AIが日常に浸透するなか、子どもたちの言語力や思考力にどう影響するのか。便利さの裏に潜むリスクと真正面から向き合う1冊。
川原 繁人著書『言語学者、生成AIを危ぶむ 子供にとって毒か薬か』から一部転載・編集してお届けいたします。
三年で学ぶ子ども、万年かけるAI
「生成AI」と「人間言語」の次なる違いについて考えていきましょう。
生成AIの特徴の一つとして「訓練データの量を増やせば増やすほど、精度があがる」という「べき乗則」が発見されています。
例えば、ChatGPTで使われているGPTでは、新しいバージョンほど訓練データの量が多く、性能があがっています。
ChatGPTの開発に使われている訓練データの詳細は公表されていませんが、ChatGPTが公開される二年前にOpenAIが発表したGPT-3では約四千億トークンが使われており、GPT-4の訓練データは、具体的な量は未発表なものの、GPT-3の倍以上ではないかと推測されています。
これらが、どれだけ膨大な量なのかを実感するために、概算となりますが計算してみましょう。
「トークン」という単位は、コンピューターが文章を理解しやすいように、単語や文字を小さく区切ったもので、言語における「単語」とは必ずしも一致しないのですが、あくまで概算ですし、結論は変わりませんから、本節では「トークン」=「単語」と簡略化します。
ここで、一秒に二単語読むと仮定すると、GPT-3やGPT-4の訓練データ量は、人間が二十四時間寝食を犠牲にして読み続けても、それぞれ約六千三百年、一万五千年以上かかる量です。
一秒に四単語読めると仮定しても、この値は半分にしかなりませんから、やはり膨大な時間がかかることがわかります。
表1に、GPTのそれぞれのバージョンに使われたトークン数と、それを人間が読むのに必要な推定年数をまとめました。
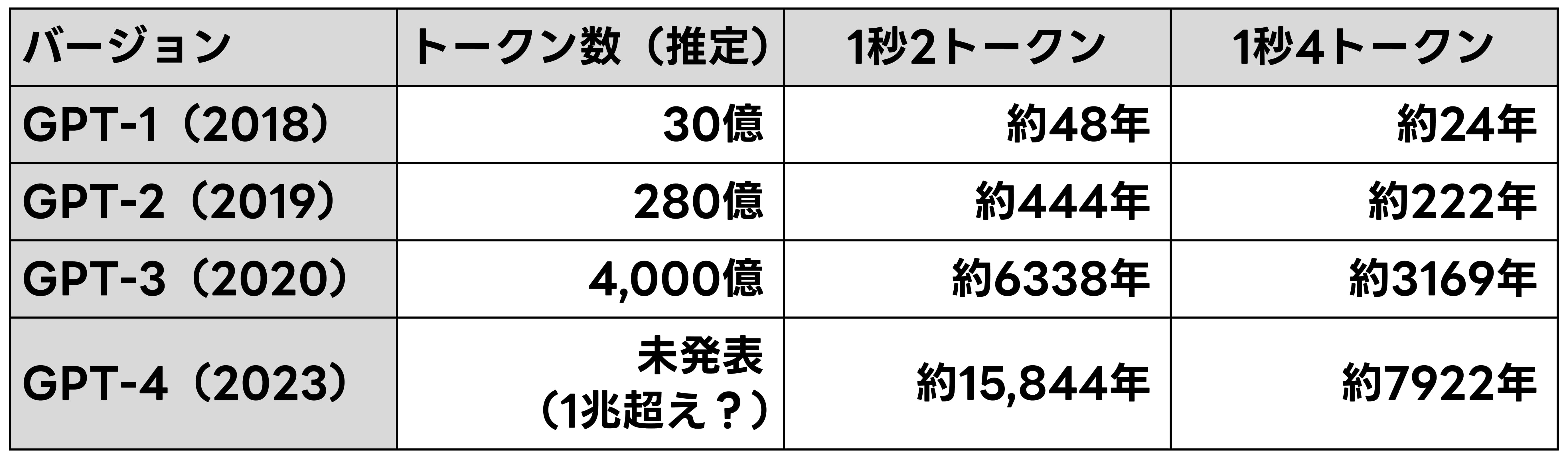
表1:GPT各バージョンの訓練に使われていると推定されているトークン数。前述の岡野原(2023:72)より。またそれらを人間が読むのにかかる推定年数
これだけ莫大な量の訓練データを必要とするのが、今の生成AIなのです。
もちろん、人間だって、読み聞かせや語りかけをたくさん受けるほど、言語能力が豊かになることは間違いありません。
ですが、赤ちゃんが基礎的な言語知識を獲得するプロセスは、たった数年で達成されるのです。
そう考えると、生成AIが人間と同じ「言語」を扱っているように見えても、その背景にある学習の仕組みは、まったく別のものであると結論づけられます。
人間の子どもは、母語を獲得するのに四千億単語も必要としません。
ですから私も妻も、生成AIの言葉を「それっぽく見えるけれど、根っこは別物」として捉えた方が、子どもの言語環境を考える上では健全ではないか、と感じています。
記事の内容がよかったら「イイね!」ボタンを押してね
このコラムに関連する書籍はこちら!









